Welcome to my homepage!
I am a second-year Computer Science Master’s student at Brown University , working on multimodal learning, Vision-Language Models (VLMs), and Large Vision-Language Models (LVLMs). My graduate research focuses on enhancing LVLM performance in complex multimodal scenarios and in-domain applications, as well as building trustworthy and robust multimodal systems powered by these models. I’m fortunate to be advised by Prof. Ellie Pavlick and Stephen Bach from Brown University, Prof. Ruixiang Tang from Rutgers University, and Dr. Ligong Han from MIT–IBM Watson AI Lab. I received my Bachelor’s degree in Artificial Intelligence from Soochow University, where my research explored retrieval-augmented generation (RAG) for LLMs and LLM evaluation, advised by Prof. Juntao Li.
, working on multimodal learning, Vision-Language Models (VLMs), and Large Vision-Language Models (LVLMs). My graduate research focuses on enhancing LVLM performance in complex multimodal scenarios and in-domain applications, as well as building trustworthy and robust multimodal systems powered by these models. I’m fortunate to be advised by Prof. Ellie Pavlick and Stephen Bach from Brown University, Prof. Ruixiang Tang from Rutgers University, and Dr. Ligong Han from MIT–IBM Watson AI Lab. I received my Bachelor’s degree in Artificial Intelligence from Soochow University, where my research explored retrieval-augmented generation (RAG) for LLMs and LLM evaluation, advised by Prof. Juntao Li.
My current and near-term multimodal research centers on the LLaVA-style “Vision encoder-Projector-LLM decoder” LVLM architecture. This framework effectively leverages the strong reasoning capabilities of LLMs while seamlessly integrating visual information into existing language-centric pipelines. Giving AI “eyes👀” is a key step toward AGI. However, relying heavily on LLMs also introduces several limitations—most notably modality bias from LLM pre-training and significant reasoning inefficiency caused by image-to-token conversion. My research directions include:
(1) Multimodal reasoning enhancement in pre-trained LVLMs. I aim to improve cross-modal alignment, reduce language priors, enhance visual perception, mitigate hallucinations, and strengthen the model’s ability to understand and utilize complex multimodal information. Thus, we can get smarter and more reliable LVLMs. My work investigates:
- Training-free methods such as prompt engineering, attention steering, contrastive decoding, and self-reflection, etc.
- Lightweight training techniques such as prompt tuning and prefix tuning.
(2) Efficient multimodal learning. In current LVLMs, each image is converted into far more tokens than text, and the resulting visual tokens are proven to be highly sparse. Meanwhile, downstream tasks often require different image resolutions. This makes adaptive and efficient inference strategies essential. My work investigates:
- Image-side methods: token pruning, resolution routing, and other adaptive image-to-token conversion techniques;
- Attention-side methods: sparse attention mechanisms tailored for visual inputs.
They can further benefit LVLM training efficiency.
(3) Data-centric multimodal foundation models. For both the pre-training and post-training stages, I study optimal training data recipes (a largely underexplored area in multimodality) as well as effective training strategies. Compared to architectural tweaks, data-centric design is at the core of LVLM advancement, as exemplified by the InternVL and QwenVL families.

The Vision encoder–Projector–LLM decoder architecture, epitomized by LLaVA. Simple yet powerful. Foundational for LVLMs. And one of my all-time favorite papers.
It is worth noting that during my Master’s research, my research mostly focused on a single topic: multimodal in-context learning (ICL). I chose this topic because it naturally involves complex multimodal scenarios, including multi-image reasoning and interleaved image–text understanding. However, most existing works study only single-image tasks. While these studies provide useful insights, they remain fundamentally different from multimodal ICL (which can be reflected in the revolution from LLaVA to LLaVA-next-interleaved). Moreover, multimodal ICL will not lose its value as commercial LVLMs rapidly improve. It enhances any model and consistently brings complementary benefits. More importantly, ICL is crucial for everyday LLM usage for ordinary users. I hope to build a comprehensive, personally distinctive, and impactful research framework around this topic. Related works that I have published can be found in the Publications section below.
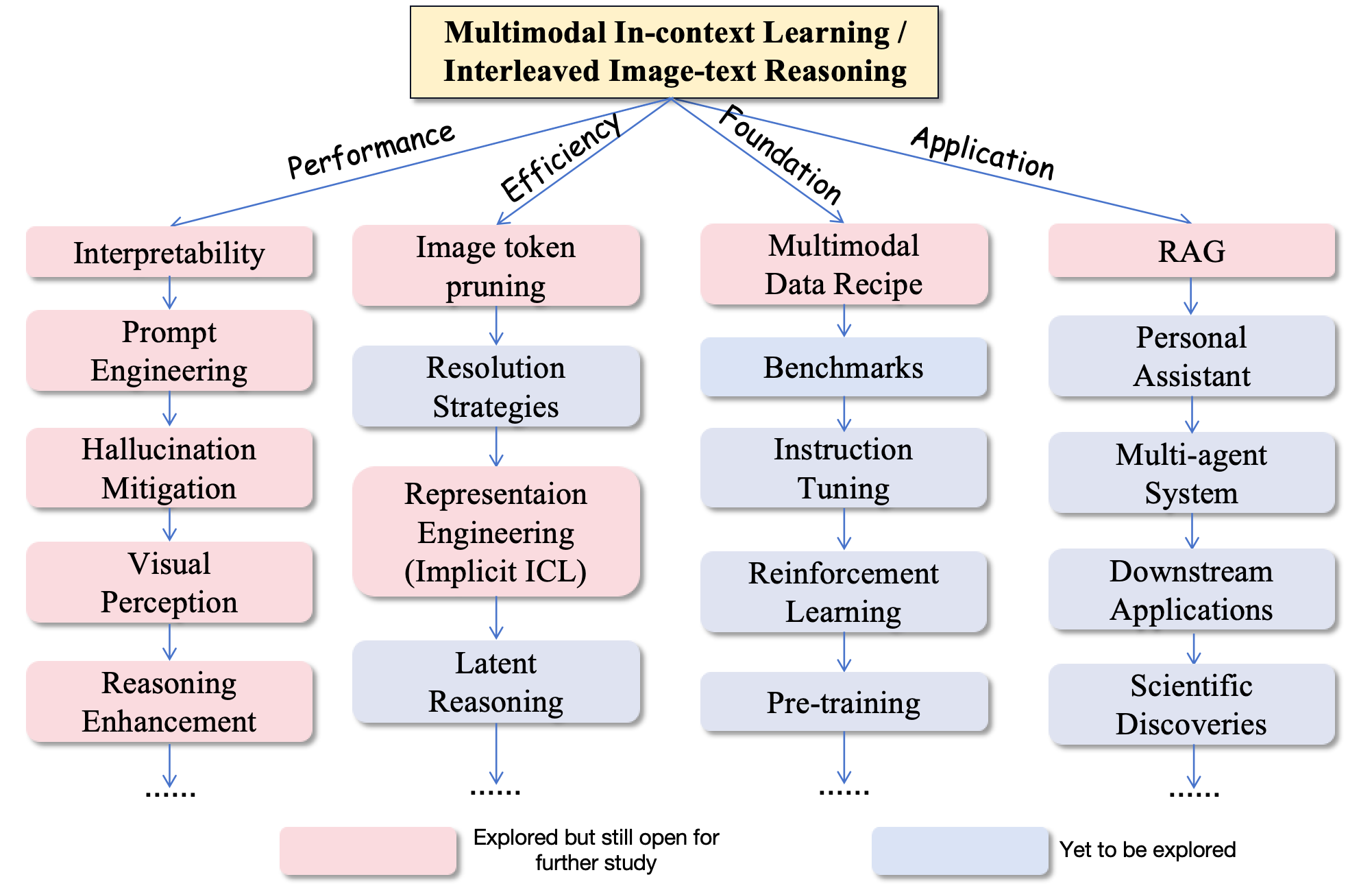
My research blueprint for advancing multimodal in-context learning.
For my long-term goals, I plan to explore several directions: 1. Multi-agent systems and agentic RL built on LVLMs. 2. Applying LVLMs to downstream domains such as healthcare, medical image analysis, and broader scientific discovery. 3. Developing vision–language alignment strategies that go beyond existing paradigms. 4. Building unified understanding–generation models that can produce both text and multimodal content, along with RL strategies grounded on such models. 5. Designing a vision-centric LVLM architecture. Please feel free to reach out to me to share your thoughts or explore any form of collaboration!
[Note] I am actively applying for Fall 2026 CS Ph.D. programs!
🔥 News
- 2025.11: 🎉🎉 Two papers are accepted at AAAI 2026 and both are selected as Oral presentations🏅! See you in Singapore!
- 2025.11: 🎉🎉 Three papers are accepted at WACV 2026!
- 2025.09: 🎉🎉 One paper is accepted at NeurIPS 2025!
- 2025.08: 🎉🎉 Three papers are accepted at EMNLP 2025 (two at the Main conference and one at Findings)! One of them is selected as an Oral presentation🏅! See you in Suzhou!
- 2025.07: 🎉🎉 One paper is accepted at COLM 2025! See you in Montreal!
- 2025.07: 🎉🎉 One paper is accepted at ACM MM 2025!
- 2025.05: 🎉🎉 One paper is accepted at ICML 2025!
- 2025.01: 🎉🎉 Two papers are accepted at ICLR 2025 Workshop and both are selected as Oral presentations🏅! See you in Singapore!
- 2024.09: 🔝🔝 I join Brown University as a Master’s student in Computer Science!
- 2024.09: 🎉🎉 One paper is accepted at NeurIPS 2024!
📝 Publications
For a complete list of publications, please visit my Google Scholar.
CAMA: Enhancing Multimodal In-Context Learning with Context-Aware Modulated Attention
Yanshu Li, Jianjiang Yang, Ziteng Yang, Bozheng Li, Hongyang He, Zhengtao Yao, Ligong Han, Yingjie Victor Chen, Songlin Fei, Dongfang Liu, Ruixiang Tang
- We propose Context-Aware Modulated Attention (CAMA), a training-free method that dynamically adjusts attention logits to fix attention deficits in LVLMs’ multimodal in-context learning. This work improves model stability, reduces erroneous attention patterns, and enhances the consistency of multimodal reasoning.
📑 Click to see abstract
Multimodal in-context learning (ICL) is becoming a key capability that allows large vision-language models (LVLMs) to adapt to novel tasks without parameter updates, which expands their usefulness in many real-world applications. However, ICL performance remains unstable even when the in-context demonstrations (ICDs) are well matched, showing that LVLMs still struggle to make full use of the provided context. While existing work mainly focuses on prompt engineering or post-hoc logit calibration, we study the attention mechanisms inside LVLMs to address their inherent limitations. We identify two important weaknesses in their self-attention that hinder effective ICL. To address these weaknesses, we propose \textbf{Context-Aware Modulated Attention} (CAMA), a plug-in and training-free method that dynamically adjusts attention logits based on the input in-context sequence. CAMA uses a two-stage modulation process that strengthens attention to semantically important tokens, especially visual ones. Across four LVLMs and seven benchmarks, CAMA consistently outperforms vanilla models and baselines, showing clear effectiveness and generalization. It can also activate the intended benefits of prompt engineering methods and remains robust across different sequence configurations. Therefore, CAMA opens up new directions for improving multimodal reasoning through a deeper understanding of attention dynamics.
CATP: Contextually Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning
Yanshu Li, Jianjiang Yang, Zhennan Shen, Ligong Han, Haoyan Xu, Ruixiang Tang
- We propose Contextually Adaptive Token Pruning (CATP), a training-free image token pruning method that adapts to complex image-text interactions and significantly reduces redundant image tokens in LVLMs. This research pushes forward the efficiency and practical applicability of multimodal in-context learning.
📑 Click to see abstract
Modern large vision-language models (LVLMs) convert each input image into a large set of tokens that far outnumber the text tokens. Although this improves visual perception, it also introduces severe image token redundancy. Because image tokens contain sparse information, many contribute little to reasoning but greatly increase inference cost. Recent image token pruning methods address this issue by identifying important tokens and removing the rest. These methods improve efficiency with only small performance drops. However, most of them focus on single-image tasks and overlook multimodal in-context learning (ICL), where redundancy is higher and efficiency is more important. Redundant tokens weaken the advantage of multimodal ICL for rapid domain adaptation and lead to unstable performance. When existing pruning methods are applied in this setting, they cause large accuracy drops, which exposes a clear gap and the need for new approaches. To address this, we propose Contextually Adaptive Token Pruning (CATP), a training-free pruning method designed for multimodal ICL. CATP uses two stages of progressive pruning that fully reflect the complex cross-modal interactions in the input sequence. After removing 77.8\% of the image tokens, CATP achieves an average performance gain of 0.6\% over the vanilla model on four LVLMs and eight benchmarks, clearly outperforming all baselines. At the same time, it improves efficiency by reducing inference latency by an average of 10.78\%. CATP strengthens the practical value of multimodal ICL and lays the foundation for future progress in interleaved image-text settings.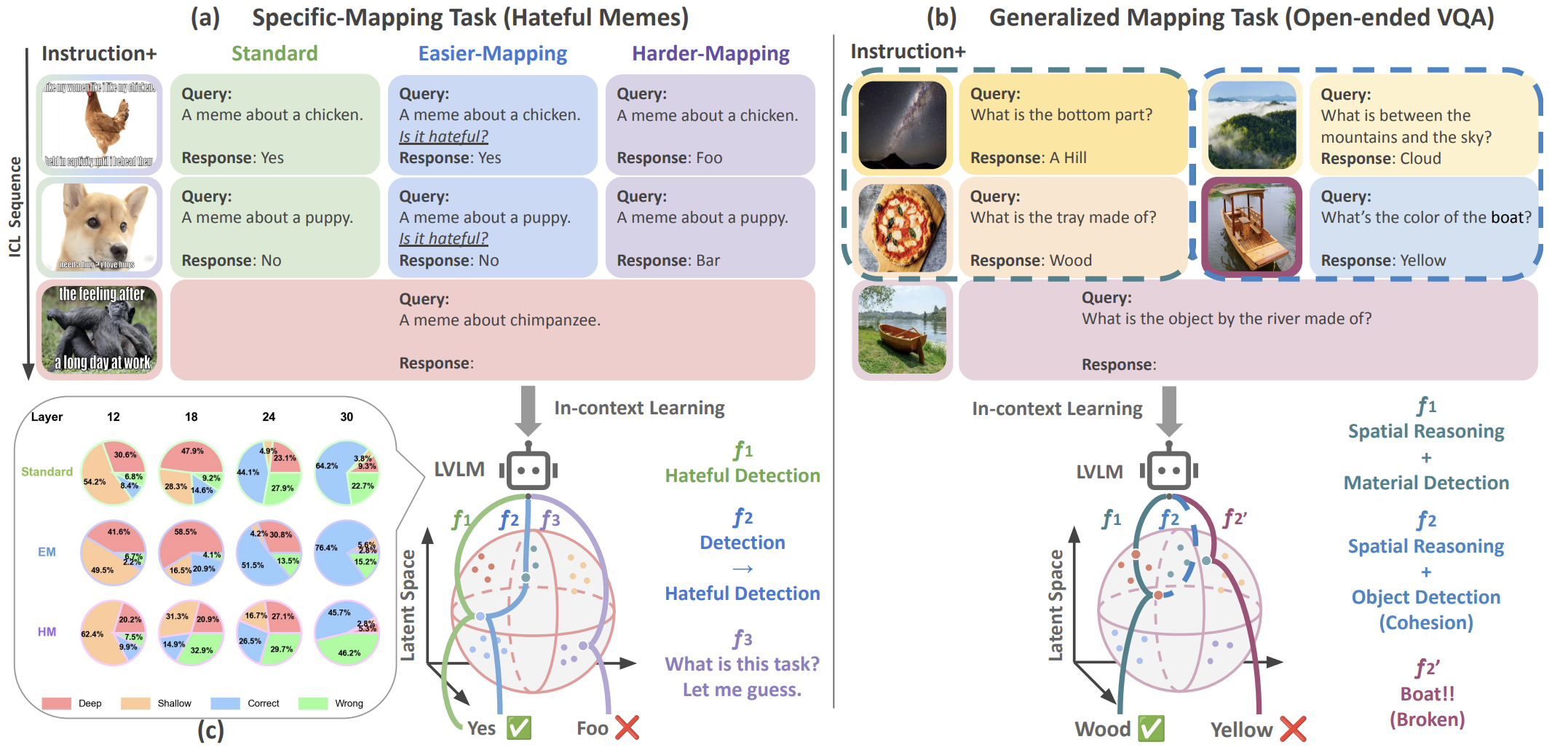
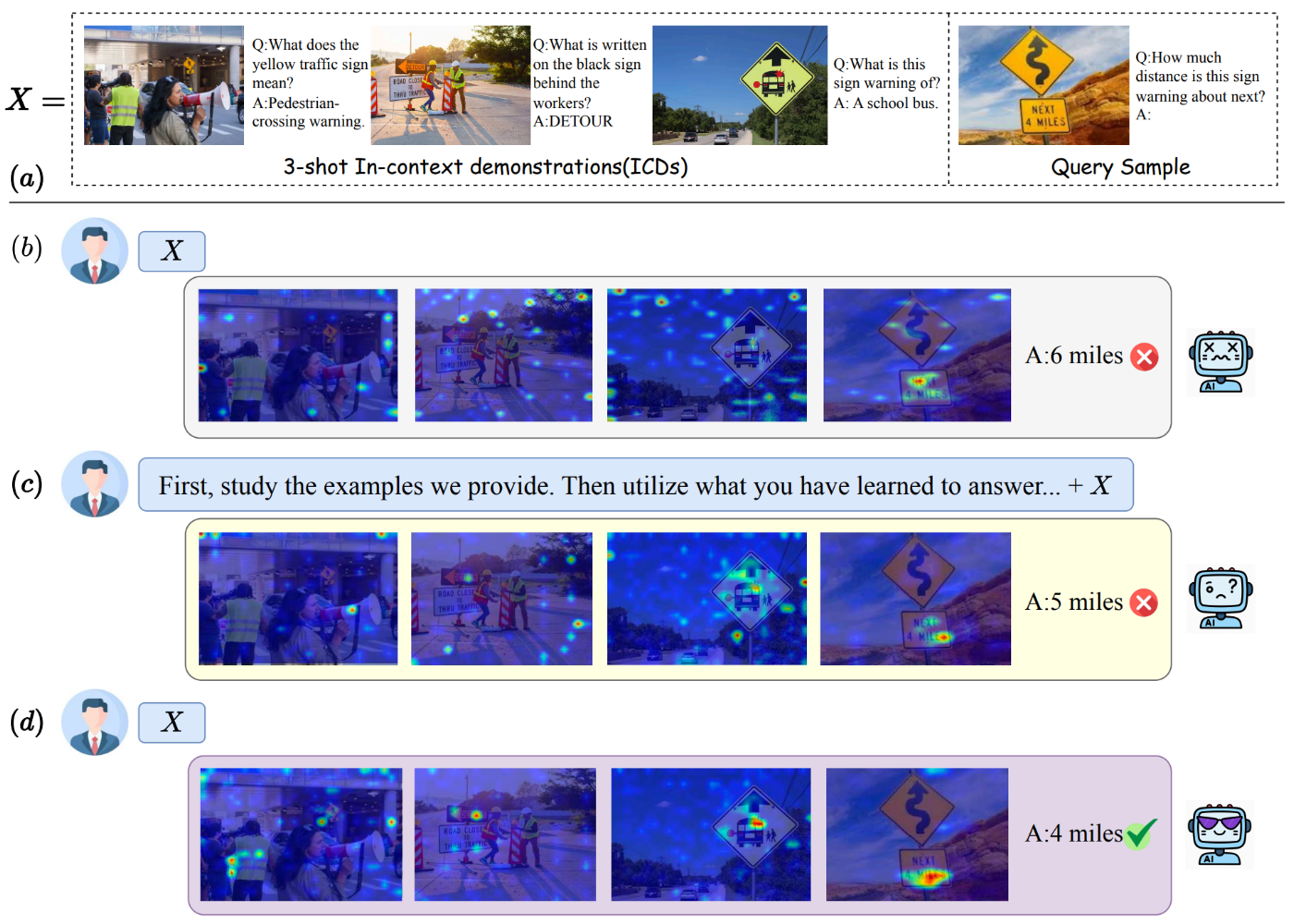
TACO: Enhancing Multimodal In-context Learning via Task Mapping-Guided Sequence Configuration
Yanshu Li, Jianjiang Yang, Tian Yun, Pinyuan Feng, Jinfa Huang, Ruixiang Tang
- We propose an interpretable framework that analyzes how multimodal in-context learning behaves under different inputs, and we further introduce TACO, a lightweight transformer-based model that uses this framework to configure in-context prompts for LVLMs. This work improves the robustness and adaptability of multimodal in-context learning pipelines by making prompt configuration more informed and controllable.
📑 Click to see abstract
Multimodal in-context learning (ICL) has emerged as a key mechanism for harnessing the capabilities of large vision–language models (LVLMs). However, its effectiveness remains highly sensitive to the quality of input ICL sequences, particularly for tasks involving complex reasoning or open-ended generation. A major limitation is our limited understanding of how LVLMs actually exploit these sequences during inference. To bridge this gap, we systematically interpret multimodal ICL through the lens of task mapping, which reveals how local and global relationships within and among demonstrations guide model reasoning. Building on this insight, we present TACO, a lightweight transformer-based model equipped with task-aware attention that dynamically configures ICL sequences. By injecting task-mapping signals into the autoregressive decoding process, TACO creates a bidirectional synergy between sequence construction and task reasoning. Experiments on five LVLMs and nine datasets demonstrate that TACO consistently surpasses baselines across diverse ICL tasks. These results position task mapping as a novel and valuable perspective for interpreting and improving multimodal ICL.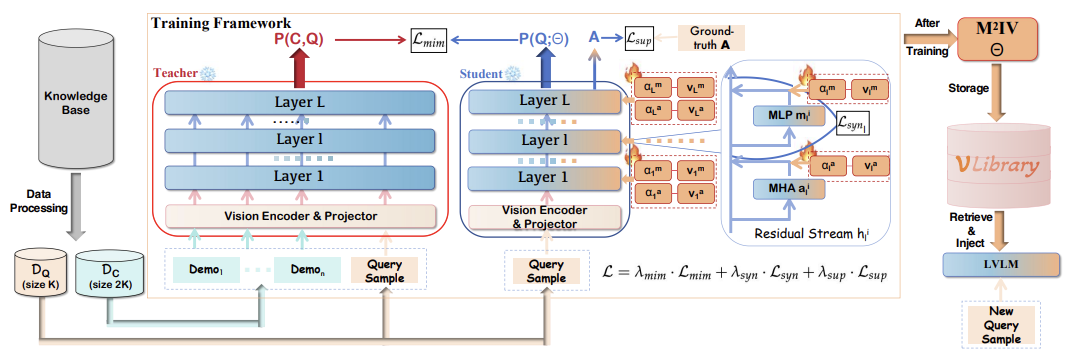
Yanshu Li, Yi Cao, Hongyang He, Qisen Cheng, Xiang Fu, Xi Xiao, Tianyang Wang, Ruixiang Tang
- We propose M²IV, a representation-engineering framework that replaces token-level demonstrations with learnable in-context vectors that can be directly injected into the layers of LVLMs for fine-grained and efficient multimodal in-context learning. This work improves scalability, reduces token overhead, and strengthens task adaptation in multimodal ICL. It also provides a promising way of customizing LVLMs.
📑 Click to see abstract
Multimodal in-context learning (ICL) equips Large Vision-language Models (LVLMs) with the ability to adapt to new tasks via multiple user-provided demonstrations, without requiring any model parameter updates. However, its effectiveness is constrained by the token-intensive nature of multimodal inputs and the complexity of cross-modal few-shot reasoning, which together hinder LVLMs from extracting useful patterns from demonstrations. To address these challenges, we propose \textbf{M²IV}, a novel representation engineering approach that replaces explicit token-level demonstrations with a set of learnable Multimodal In-context Vectors directly injected into the residual streams of LVLMs. By analyzing the distinct roles of multi-head attention (MHA) and multi-layer perceptrons (MLP) in the ICL process, we design a training strategy that enables M²IV to perform fine-grained semantic distillation and robust cross-modal representation learning. M²IV not only improves performance across diverse tasks and LVLMs but also significantly reduces token overhead, enabling graceful scaling to many-shot scenarios. To further enhance usability, we introduce \textbf{VLibrary}, a repository that stores trained M²IVs for flexible retrieval and injection. With VLibrary, users can steer pre-trained LVLMs in a customized manner that meets diverse requirements. Extensive experiments demonstrate that M²IV consistently outperforms vanilla ICL and prior representation engineering baselines, achieving an average accuracy gain of 3.74\% with substantial improvements in overall efficiency.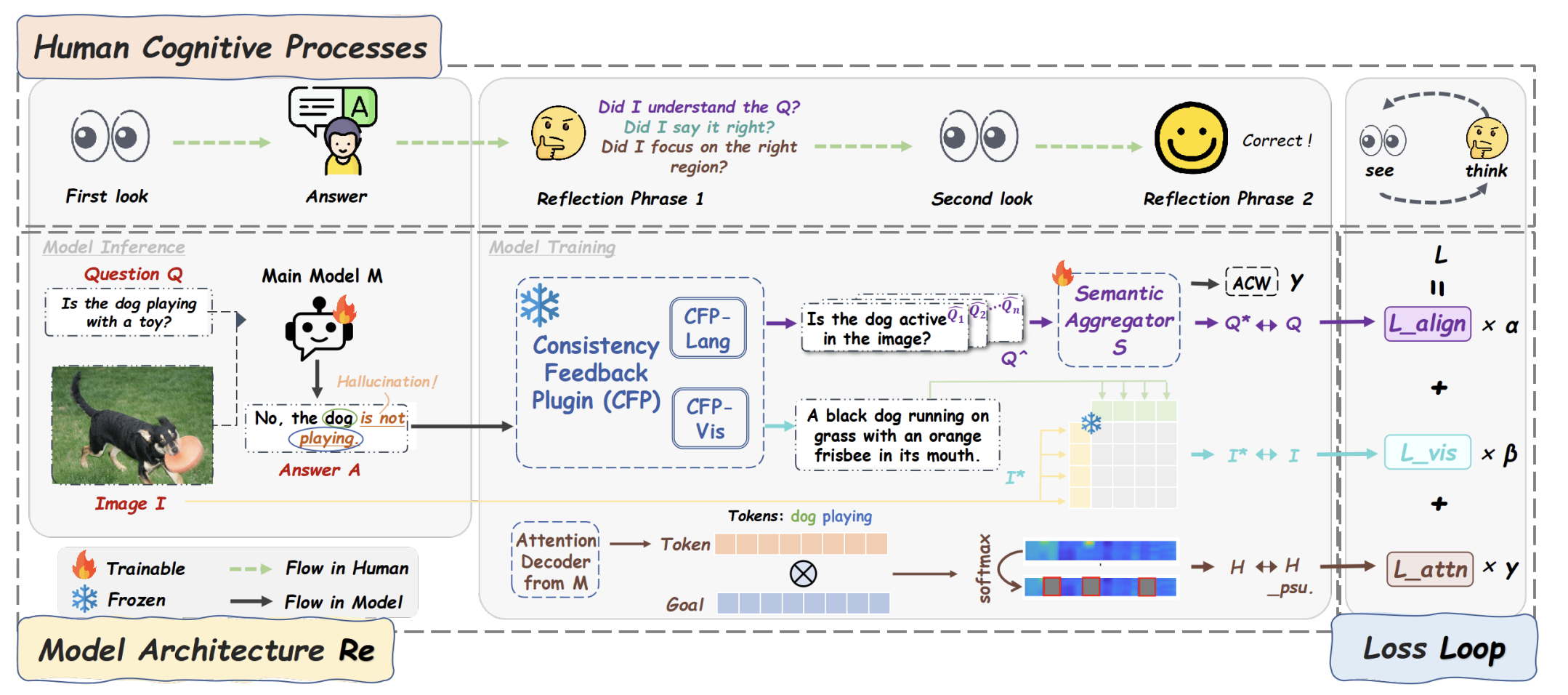
Jianjiang Yang, Yanshu Li, Ziyan Huang
- We propose ReLoop, a closed-loop training framework that reduces hallucinations by enforcing multimodal consistency through semantic reconstruction, visual description, and attention alignment. This work strengthens the faithfulness and stability of multimodal understanding by enabling models to better verify and correct their own predictions.
📑 Click to see abstract
While Multimodal Large Language Models (MLLMs) have achieved remarkable progress in open-ended visual question answering, they remain vulnerable to hallucinations. These are outputs that contradict or misrepresent input semantics, posing a critical challenge to the reliability and factual consistency. Existing methods often rely on external verification or posthoc correction, lacking an internal mechanism to validate outputs directly during training. To bridge this gap, we propose ReLoop, a unified closed-loop training framework that encourages multimodal consistency for cross-modal understanding in MLLMs. ReLoop adopts a ring-shaped structure that integrates three complementary consistency feedback mechanisms, obliging MLLMs to" seeing twice and thinking backwards". Specifically, ReLoop employs the frozen Consistency Feedback Plugin (CFP), comprising semantic reconstruction and visual description modules, along with an attention supervision module for attention alignment. These components collectively enforce semantic reversibility, visual consistency, and interpretable attention, enabling the model to correct its outputs during training. Extensive evaluations and analyses demonstrate the effectiveness of ReLoop in reducing hallucination rates across multiple benchmarks, establishing a robust method for hallucination mitigation in MLLMs. The code is available at: https://github. com/ZiyanHuang11/Reloophallucinations.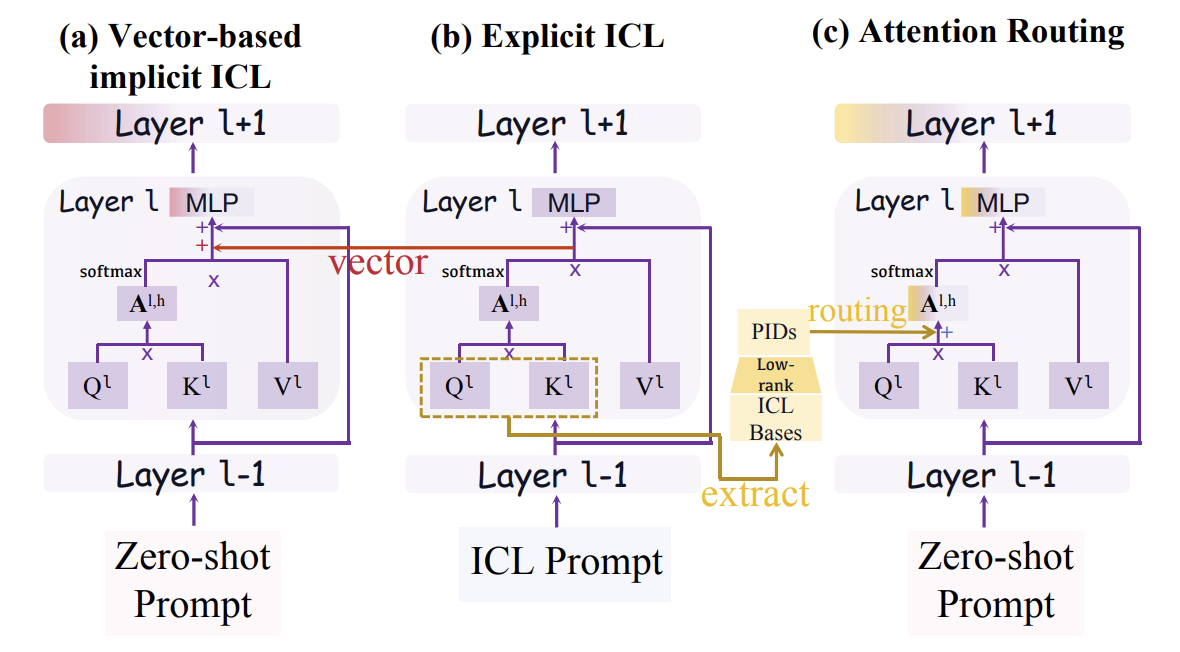
Towards Generalizable Implicit In-Context Learning with Attention Routing
Jiaqian Li, Yanshu Li, Ligong Han, Ruixiang Tang, Wenya Wang
- We propose In-context Routing (ICR), a mechanism within implicit in-context learning that dynamically routes attention paths in the logits space to simulate few-shot behavior without relying on explicit demonstrations or steering vectors added on activations. This work elevates the generalizability of implicit in-context learning, enabling models to adapt more flexibly across diverse tasks.
📑 Click to see abstract
Implicit in-context learning (ICL) has newly emerged as a promising paradigm that simulates ICL behaviors in the representation space of Large Language Models (LLMs), aiming to attain few-shot performance at zero-shot cost. However, existing approaches largely rely on injecting shift vectors into residual flows, which are typically constructed from labeled demonstrations or task-specific alignment. Such designs fall short of utilizing the structural mechanisms underlying ICL and suffer from limited generalizability. To address this, we propose In-Context Routing (ICR), a novel implicit ICL method that internalizes generalizable ICL patterns at the attention logits level. It extracts reusable structural directions that emerge during ICL and employs a learnable input-conditioned router to modulate attention logits accordingly, enabling a train-once-and-reuse framework. We evaluate ICR on 12 real-world datasets spanning diverse domains and multiple LLMs. The results show that ICR consistently outperforms prior implicit ICL methods that require task-specific retrieval or training, while demonstrating robust generalization to out-of-domain tasks where existing methods struggle. These findings position ICR to push the boundary of ICL's practical value.NeruIPS 2025TRiCo: Triadic Game-Theoretic Co-Training for Robust Semi-Supervised Learning Hongyang He, Xinyuan Song, Yangfan He, Zeyu Zhang, Yanshu Li, Haochen You, Lifan Sun, Wenqiao Zhang
SurveyThinking with Images for Multimodal Reasoning:
Foundations, Methods, and Future Frontiers Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, Linjie Li, Yu Cheng, Heng Ji, Junxian He, Yi R. Fung
ACM MM 2025Draw with Thought: Unleashing Multimodal Reasoning for Scientific Diagram Generation
Zhiqing Cui, Jiahao Yuan, Hanqing Wang, Yanshu Li, Chenxu Du, Zhenglong Ding
📖 Educations
- 2024.9 - 2026.5 (Expected), Master’s in Computer Science, Brown University, Providence, Rhode Island, USA. Advised by Ellie Pavlick and Stephen Bach.
- 2025.1 - present, Research Internship, Rutgers University, New Brunswick, New Jersey, USA. Advised by Ruixiang Tang.
- 2020.9 - 2024.6, Bachelor in Artificial Intelligence, Soochow University, Suzhou, Jiangsu, China. Advised by Juntao Li.
💻 Internships
- 2024.04-2024.06, Foundation Model Engineer, Baidu, Shanghai, China
- 2023.10-2024.02, Foundation Model Engineer, iFlytek, Suzhou, China
⚙️ Services
- Volunteer: COLM 2024, COLM 2025, ICLR 2025, EMNLP 2025
- Reviewer: ARR Feb/May/Jul/Oct 2025, COLM 2025, NeurIPS 2025, AAAI 2026, ICLR 2026
🪄 Misc
I’m an ACGN (Anime, Comic, Game, Novel) fan and a cosplayer. If you share similar interests, feel free to reach out for 扩列/友達募集!